Tsvetan's Blog
Hey! Here you can find my digital garden. Feel free to reach me out at tsvetan @ camplight net.
Caching vs. data duplication
In this article I’m going to explore several solutions to the problem of latency in distributed systems.
We have the following distributed system.
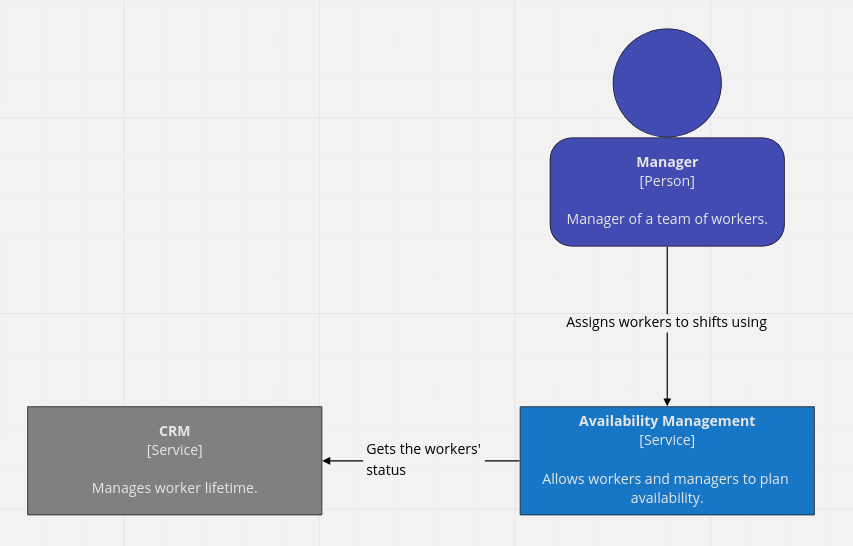
In it, the Availability Management service needs to be aware of the worker’s status. It retrieves it from the CRM. The Availability Management service and the CRM service are under different teams.
The current architecture makes synchronous calls to the CRM to retrieve the worker’s status whenever it’s needed. However, the Availability Management team has started to experience latency issues with this approach.
Possible Solutions
The team considered two solutions to this problem:
- Caching the workers’ status in the Availability Management service;
- Collaborating with the CRM service to implement a read-only copy of the data inside the Availability Management service.
Let’s explore both.
Caching
Caching is a mechanism that stores data that’s about to be used near the user of that data. This lets the user retrieve the data with low latency at most times. However, there are occasions where the data isn’t in the cache, so a round trip to the data source has to be made. A usual caching architecture looks like the following.
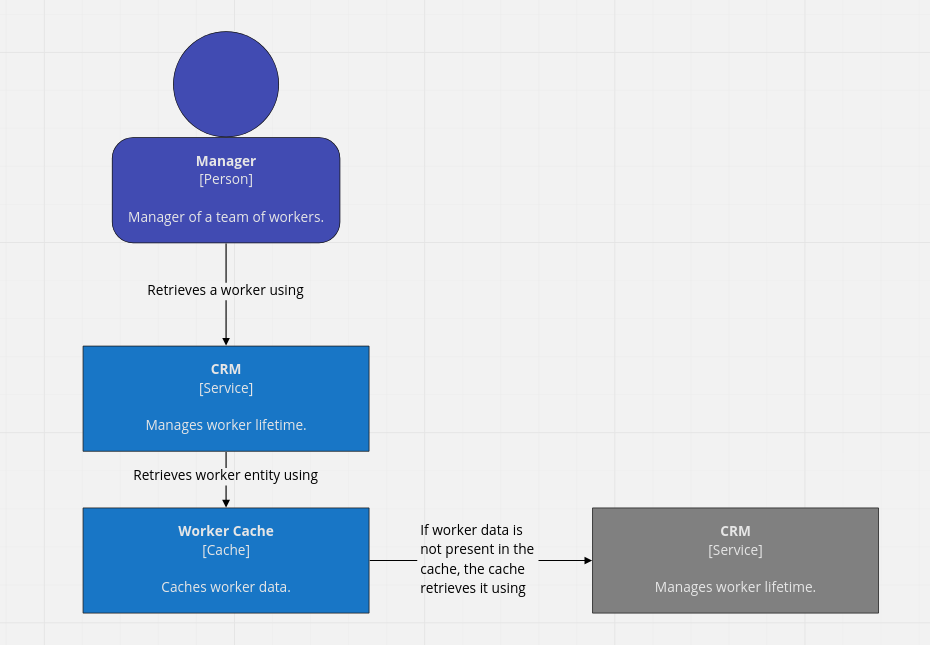
Whenever the CRM service wants to retrieve a worker from the Worker DB, it goes through the Worker Cache. If the worker is in the cache, there’s a cache hit and no DB call is made. Otherwise, a cache miss occurs and the worker data has to be retrieved from the Worker DB and saved in the Worker Cache for future use.
There are several important aspects of a cache.
- The cache is limited in size;
- You either get a cache miss or a cache hit. You aren’t guaranteed what you’re going to get with each retrieval operation;
- Each item in the cache has Time to Live (TTL). This guarantees that eventually you’re going to get an updated copy of the cached item.
Let’s examine each and see how they’re going to affect our solution.
Aspects of a Cache
The cache is limited in size. This means that we may not be able to store the whole Worker DB in the cache. So, after a certain number of items are cached, we’ll have to remove items from the cache if we want to continue using it effectively. This is done via a wide range of cache replacement algorithms (I’m not going to dive deeper into these).
You either get a cache miss or a cache hit. Until the cache is populated or due to its size limitations, some data won’t be in it. Whenever that happens, you get a cache miss and you have to query the database to retrieve the needed data.
Each item in the cache has Time to Live (TTL). This is needed because the data in the database may change. If items lived in the cache indefinitely, items that weren’t replaced might become stale. The TTL ensures that an item will be out of date in a limited time frame.
All three lead to the fact that caches can’t guarantee predictable latency for each retrieval. If you get a cache hit items are going to be retrieved faster. Otherwise, they won’t. Also, you’ll have to preserve a fine balance between a long-enough TTL to prevent cache miss and short enough so you limit the amount of stale data you work with.
Other Considerations
When dealing with caches, you also have to keep in mind the Thundering Herd problem. In short, if lots of cache clients try to access the same item at the same time from the database due to cache miss, the database might be unable to handle the load. This might happen when the cache goes down for some reason or if a frequently accessed item suddenly becomes invalid.
Lastly, in this team’s case, the cache is going to couple the Availability Management and the CRM service. If the CRM team decides to change the service behind the cache for some reason, the cache will also have to be changed by the Availability Management team.
Given these considerations, the team decides to leave caching for now and explore the second solution.
Read-Only Copy
The next solution that the team comes up with looks like the following.
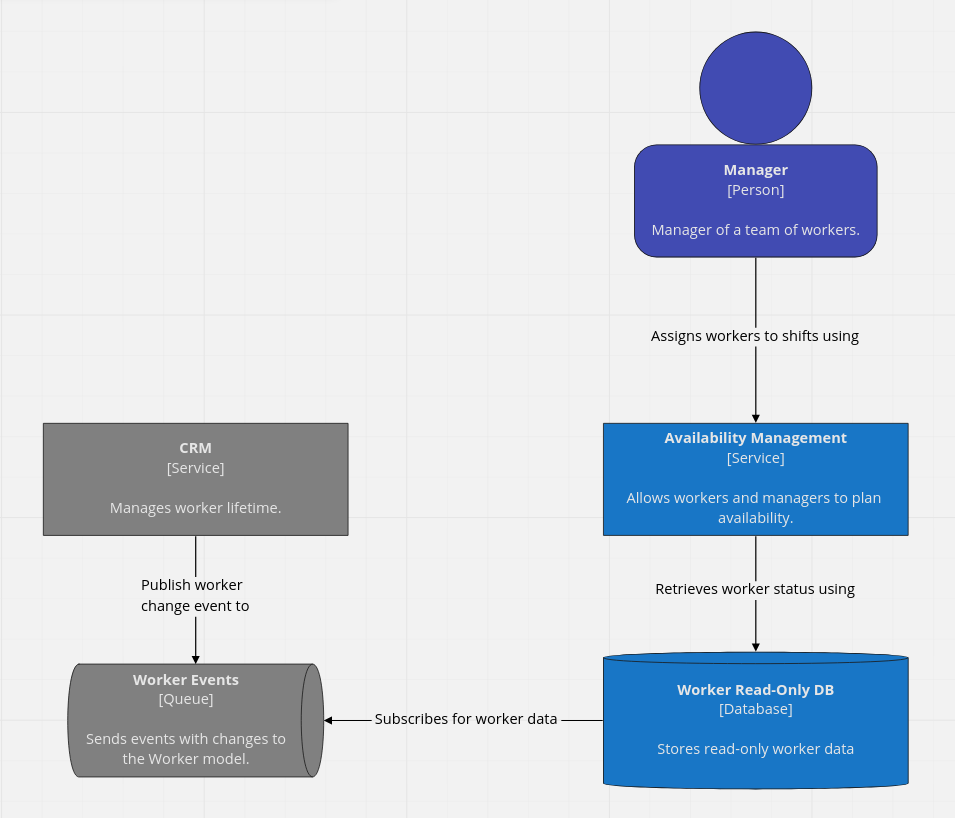
This solution relies on having an eventually consistent copy of worker data in a database that’s owned by the Availability Management Service. Each time the worker data in the CRM Service is updated an event gets published to the Worker Events Queue. The Worker Read-Only DB gets the latest event from the queue and updates its data.
There are several important things to consider in this architecture:
- The CRM Service has to ensure at least once delivery of events to the Worker Events Queue. This is achieved by following the Transactional Outbox Pattern;
- The Worker Read-Only DB has to consume events idempotently.
This architecture overcomes the limitations of the caching solution in exchange of having to store a potentially big amount of worker data in the bounded context of Availability Management.
- It’s not limited in size as the database can be expanded on demand;
- You always rely on the database to retrieve data. This ensures predictable low latency;
- Even if the CRM Service or the Worker Events Queue go down, the Availability Management Service can continue to work. This leads to increased availability of the overall system;
- Both systems are decoupled. The CRM Service team doesn’t need to know much about the Availability Management Service. It just needs to ensure the event contract is observed. Also, if more systems need to use the worker data in some way, they can subscribe to the Worker Events Queue.
Based on the above, the team decides to move forward with having a read-only copy of the worker data. This will definitely require more collaboration with the CRM team at the beginning until they setup the Worker Events Queue. However, once this is done, everything else falls into the realm of the Availability Management team.
Conclusion
Having two tightly coupled components relying on synchronous communication is simple but when the system starts to scale, latency and availability issues start to pop up. If strong consistency is not a hard requirement, this can be overcome by incorporating caching or moving towards an event-driven architecture. Both have their trade-offs. We choose to move towards an event-driven architecture as it decouples the systems and provides predictable latency.
Leave your email if you want to receive more essays like this